This is the third part of Testing with Kafka for JUnit. See the table underneath for links to the other parts.
In this article, we'll shift our attention away from component tests and will take a look at how you can leverage Kafka for JUnit in order to write system tests at a higher level of abstraction. A couple of years ago, I was exploring Spring for Kafka and implemented a couple of showcases along the way. One of these showcases is a small system of microservices that implement a solution for managing todo's according to David Allen's Getting Things Done method. This system of microservices follows a CQRS-style architecture with a dedicated microservice - call it command service - that is concerned with altering data and another dedicated microservice - call it query service - which serves the read model. The following diagram shows how these systems interact with each other.
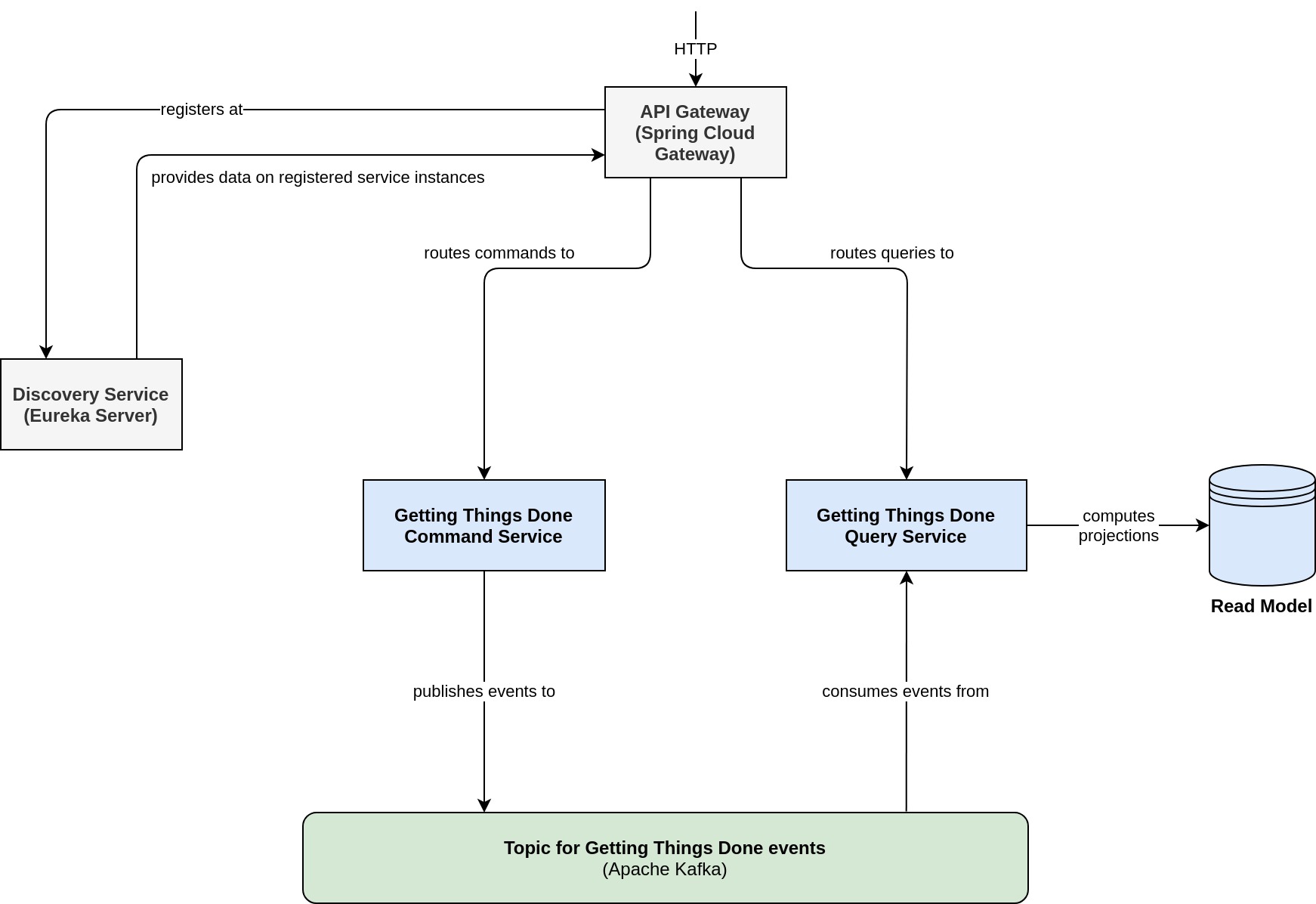
As you can see, the command service publishes domain events to a dedicated Kafka topic. The key of each and every record is a String-based aggregate ID that identifies the todo item. This makes sure that all events for the same aggregate are stored in the same topic-partition, thus letting us leverage Kafka's ordering guarantees. We are going to use Kafka for JUnit to verify that the command service integrates properly with Apache Kafka.
Without going into the details of the actual HTTP API that drives this solution, let me show you a simple client interface that I've implemented using OpenFeign.
public interface GettingThingsDone {
@RequestLine("POST /items")
@Headers("Content-Type: application/json")
Response createItem(CreateItem payload);
@RequestLine("PUT /items/{itemId}")
@Headers("Content-Type: application/json")
Response updateItem(@Param("itemId") String itemId, UpdateItem payload);
@RequestLine("GET /items/{itemId}")
@Headers("Accept: application/json")
Item getItem(@Param("itemId") String itemId);
@RequestLine("GET /items")
@Headers("Accept: application/json")
List<Item> getItems();
}
So, if we'd like to create a new todo item, we'll use the createItem method and pass the proper payload. The CreateItem class is a simple Jackson-annotated POJO that encapsulates a description for the todo item. Upon receipt, the command service will assign a unique aggregate ID to the newly created item and publish an AvroItemEvent to the log. That's right: The published interface of the command service uses Apache Avro for serialization. Since Kafka for JUnit gives you full access to the configuration of the underlying Kafka consumer, hooking up specific serialization and deserialization strategies is straightforward. Here is an excerpt of the Avro schema for the Getting Things Done solution.
{
"namespace": "net.mguenther.gtd.kafka.serialization",
"type": "record",
"name": "AvroItemEvent",
"fields": [
{
"name": "eventId",
"type": "string"
},
{
"name": "timestamp",
"type": "long"
},
{
"name": "data",
"type": [
{
"name": "AvroItemCreated",
"type": "record",
"fields": [
{
"name": "itemId",
"type": "string"
},
{
"name": "description",
"type": "string"
}
]
},
{
"name": "AvroItemConcluded",
"type": "record",
"fields": [
{
"name": "itemId",
"type": "string"
}
]
},
... omitted other events for the sake of simplicity ...
]
}
]
}
Internally, the command and query service use a conversion strategy that mediates between Avro records (AvroItemEvent) and their domain event counterparts (subclasses of ItemEvent). This is good practice: Avro records are a technical detail of our messaging and - for that matter - storage layer. Thus, these records should be treated as simple transport objects. As they are auto-generated from an Avro schema, there is no proper way to implement specific business logic into these classes. Nor is there any need for it. That's what the ItemEvent class with all of its derivatives is for. So, whenever we working on the business logic for either the command or query service, we'll work with ItemEvent instead of AvroItemEvent. The base class ItemEvent is shown underneath.
abstract public class ItemEvent {
private final String eventId;
private final long timestamp;
private final String itemId;
public ItemEvent(String itemId) {
this(UUID.randomUUID().toString().substring(0, 7), System.currentTimeMillis(), itemId);
}
public ItemEvent(String eventId, long timestamp, String itemId) {
this.eventId = eventId;
this.timestamp = timestamp;
this.itemId = itemId;
}
public String getEventId() {
return eventId;
}
public long getTimestamp() {
return timestamp;
}
public String getItemId() {
return itemId;
}
}
A specific implementation of ItemEvent is ItemCreatedEvent.
public class ItemCreated extends ItemEvent {
private final String description;
public ItemCreated(String itemId, String description) {
super(itemId);
this.description = description;
}
public ItemCreated(String eventId, long timestamp, String itemId, String description) {
super(eventId, timestamp, itemId);
this.description = description;
}
public String getDescription() {
return description;
}
@Override
public String toString() {
return String.format(Locale.getDefault(), "ItemCreated{eventId=%s, itemId=%s, description=%s}", getEventId(), getItemId(), getDescription());
}
}
We'll make use of this in our test cases as well.
Let's dive right into it and write a test that works against a running instance of the whole system and verifies that a successfully handled item creation is followed by the publication of the proper event. We won't need to use the embedded broker of Kafka for JUnit, but rather connect with an existing cluster using ExternalKafkaCluster.at(String). Suppose this cluster is accessible via localhost:9092. Then
ExternalKafkaCluster kafka = ExternalKafkaCluster.at("http://localhost:9092");
will give us access to the cluster just like we'd have access to an embedded Kafka cluster using EmbeddedKafkaCluster (remember, we've used this in previous articles to write component tests). Of course, the capabilities of the ExternalKafkaCluster are a bit more restricted, since the cluster is not under control of Kafka for JUnit. For instance, you cannot shutdown individual brokers in order to exercise the resilience of the system. These kind of tests should be written as component tests with Kafka for JUnit (see the previous articles of this series). Have a look at the user's guide to learn more about the differences between an EmbeddedKafkaCluster and an ExternalKafkaCluster.
Once we've got the ExternalKafkaCluster bound properly, we'll go on and use the GettingThignsDone HTTP client to dispatch a request that ought to create a new todo item.
GettingThingsDone gtd = createGetthingThingsDoneClient();
CreateItem payload = new CreateItem("Buy groceries!");
Response response = gtd.createItem(payload);
Remember that the key of a published AvroItemEvent record is the ID of the aggregate that the event belongs to. The HTTP response contains a Location-header that points to the newly created todo item aggregate. We'll use a method called extractItemId (details omitted) to extract the aggregate ID from the Location-header.
String itemId = extractItemId(response)
Let's observe the target topic - call it topic-gettings-things-done - for some amount of time and see if the expected event gets published. The observe and observeValues method of Kafka for JUnit can be used to check if there are any records present (with respect to the applied filters). Both methods can also be used to pull out the respective records and transform them, so that you can apply further checks. The differentation between observe and observeValues is in the return type: While the first pulls out a list of KeyValue<K, V>, the latter pulls out the values as a list of V.
In our case the parameterized type of V is an AvroItemEvent. By configuring the proper deserializer and applying a filter on the keys that matches on the itemId of the target aggregate, we ensure that only those records are pulled out of the topic that actually belong to the newly created item aggregate.
List<AvroItemEvent> publishedEvents = kafka
.observeValues(on("topic-getting-things-done", 1, AvroItemEvent.class)
.observeFor(10, TimeUnit.SECONDS)
.with(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, ItemEventDeserializer.class)
.filterOnKeys(aggregateId -> aggregateId.equals(itemId)));
Kafka for JUnit will throw an AssertionError if it could not observe a Kafka record matches the given criteria. This AssertionError would restate the expectation and how long it waited:
Expected 1 records, but consumed only 0 records before ran into timeout (10000 ms).
With the List<AvroItemEvent> at hand, we are now free to perform the required checks directly on the AvroItemEvent, but I find that rather cumbersome. Hence, I will convert these events into their domain event counterpart, pull out the first one and assert that this is indeed an event of type ItemCreated with the proper attributes present.
ItemCreated itemCreatedEvent = publishedEvents.stream()
.findFirst()
.map(converter::convert)
.map(e -> (ItemCreated) e)
.orElseThrow(AssertionError::new);
assertThat(itemCreatedEvent.getItemId(), equalTo(itemId));
assertThat(itemCreatedEvent.getDescription(), equalTo("Buy groceries!"));
For the sake of completeness, here is the whole test class.
/** regular imports omitted for brevity */
import static net.mguenther.kafka.junit.ObserveKeyValues.on;
import static org.hamcrest.MatcherAssert.assertThat;
import static org.hamcrest.Matchers.equalTo;
public class EventPublicationTest {
private static final String URL = "http://localhost:8765/api";
private final ItemEventConverter converter = new ItemEventConverter();
@Test
public void anItemCreatedEventShouldBePublishedAfterCreatingNewItem() throws Exception {
ExternalKafkaCluster kafka = ExternalKafkaCluster.at("http://localhost:9092");
GettingThingsDone gtd = createGetthingThingsDoneClient();
String itemId = extractItemId(gtd.createItem(new CreateItem("I gotta do my homework!")));
List<AvroItemEvent> publishedEvents = kafka
.observeValues(on("topic-getting-things-done", 1, AvroItemEvent.class)
.observeFor(10, TimeUnit.SECONDS)
.with(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, ItemEventDeserializer.class)
.filterOnKeys(aggregateId -> aggregateId.equals(itemId)));
ItemCreated itemCreatedEvent = publishedEvents.stream()
.findFirst()
.map(converter::to)
.map(e -> (ItemCreated) e)
.orElseThrow(AssertionError::new);
assertThat(itemCreatedEvent.getItemId(), equalTo(itemId));
assertThat(itemCreatedEvent.getDescription(), equalTo("I gotta do my homework!"));
}
private GettingThingsDone createGetthingThingsDoneClient() {
return Feign.builder()
.client(new ApacheHttpClient())
.encoder(new JacksonEncoder())
.decoder(new JacksonDecoder())
.logger(new Slf4jLogger(GettingThingsDone.class))
.logLevel(Logger.Level.FULL)
.target(GettingThingsDone.class, URL);
}
private String extractItemId(final Response response) {
return response.headers()
.get("Location")
.stream()
.findFirst()
.map(s -> s.replace("/items/", ""))
.orElseThrow(AssertionError::new);
}
}
And that's it! We've written our first system test that verifies that the integration between the command service and Apache Kafka is working correctly. You'll find the full source code for this example at GitHub. Of course, Kafka for JUnit offers more options than I was able to demonstrate in this example. Check out the comprehensive user's guide to learn more!

