This is the first part of Testing with Kafka for JUnit. See the table underneath for links to the other parts.
Kafka for JUnit makes it easy to write integration tests for custom-built Kafka-enabled components as well as entire systems that integrate with a Kafka cluster. In the course of this article, I'd like to demonstrate how you can leverage this testing library to write whitebox tests for software components that integrate with Kafka. We'll start off with the write-path of a small lifecycle event service and implement a custom publisher on top of the Kafka Clients library that ought to be tested.
Suppose we have a generic Publisher<T> interface that provides the means to log a typed payload, supporting both the asynchronous programming model from the underlying Kafka Client library and additionally a couple of blocking methods that perform the same operation.
public interface Publisher<T> extends Closeable {
Future<RecordMetadata> log(T payload);
default RecordMetadata logSync(T payload) throws InterruptedException {
try {
return log(payload).get();
} catch (ExecutionException e) {
throw new PublisherException(e.getCause());
}
}
default RecordMetadata logSync(T payload, Duration duration) throws InterruptedException {
try {
return log(payload).get(duration.toMillis(), TimeUnit.MILLISECONDS);
} catch (ExecutionException e) {
throw new PublisherException(e.getCause());
} catch (TimeoutException e) {
throw new PublisherException(e);
}
}
@Override
void close();
}
Of course, we have to provide an actual implementation for the log method. In this example, we are concerned with publishing lifecycle events for sensors of wind turbines and therefore track if a wind turbine is admissible to send metrics to a downstream service. This is only the case if it is registered as an active turbine. A TurbineRegisteredEvent will be published to a dedicated topic if a wind turbine has been successfully registered. This works analoguously for the TurbineDeregisteredEvent that removes the associated turbine from the pool of active ones.
The base class for these lifecycle events - call it TurbineEvent - is shown in the listing below. We are going to use Jackson to serialize and deserialize these events to JSON.
@JsonTypeInfo(
use = JsonTypeInfo.Id.NAME,
include = JsonTypeInfo.As.EXISTING_PROPERTY,
property = "type")
@JsonSubTypes({
@JsonSubTypes.Type(
value = TurbineRegisteredEvent.class,
name = TurbineRegisteredEvent.TYPE),
@JsonSubTypes.Type(
value = TurbineDeregisteredEvent.class,
name = TurbineDeregisteredEvent.TYPE)
})
public abstract class TurbineEvent {
private final UUID eventId;
private final String turbineId;
private final long timestamp;
@JsonCreator
public TurbineEvent(@JsonProperty("eventId") UUID eventId,
@JsonProperty("turbineId") String turbineId,
@JsonProperty("timestamp") long timestamp) {
this.eventId = eventId;
this.turbineId = turbineId;
this.timestamp = timestamp;
}
public TurbineEvent(String turbineId) {
this(UUID.randomUUID(), turbineId, System.currentTimeMillis());
}
public abstract String getType();
/** getters omitted for brevity **/
/** toString() implementation omitted for brevity **/
}
Both subtypes of this base class add a couple of things here and there. I'll omit their class definition. If you're interested, there is a GitHub repository which contains the full source code that was used for this example.
Of course, we have to implement a Serializer for TurbineEvents which translates the resp. POJO into its JSON representation and returns it as a byte[].
public final class TurbineEventSerializer implements Serializer<TurbineEvent> {
private final ObjectMapper mapper = new ObjectMapper();
@Override
public byte[] serialize(String topic, TurbineEvent data) {
try {
return mapper.writeValueAsBytes(data);
} catch (JsonProcessingException e) {
throw new PublisherException(e);
}
}
}
With the event types and a serializer in place, we can finally implement the last missing part: A sub type of Publisher<T> that is able to work with TurbineEvents.
public class TurbineEventPublisher implements Publisher<TurbineEvent> {
private final Producer<String, TurbineEvent> underlyingProducer;
private final String topic;
public TurbineEventPublisher(final String topic,
final Map<String, Object> userSuppliedConfig) {
final var config = new HashMap<>(userSuppliedConfig);
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, TurbineEventSerializer.class.getName());
this.underlyingProducer = new KafkaProducer<>(config);
this.topic = topic;
}
@Override
public Future<RecordMetadata> log(final TurbineEvent payload) {
final var record = new ProducerRecord<>(topic, payload.getTurbineId(), payload);
return underlyingProducer.send(record);
}
@Override
public void close() {
underlyingProducer.close();
}
}
If you've worked with Kafka before, none of the shown listings should contain any big surprises for you. The design is limited to submitting single records per call to log and we are not concerned with any of the more involved features - or turning this thing into a production-grade publisher for that matter. To clarify, here's an overview of all the classes and interfaces that contribute to the write-path.
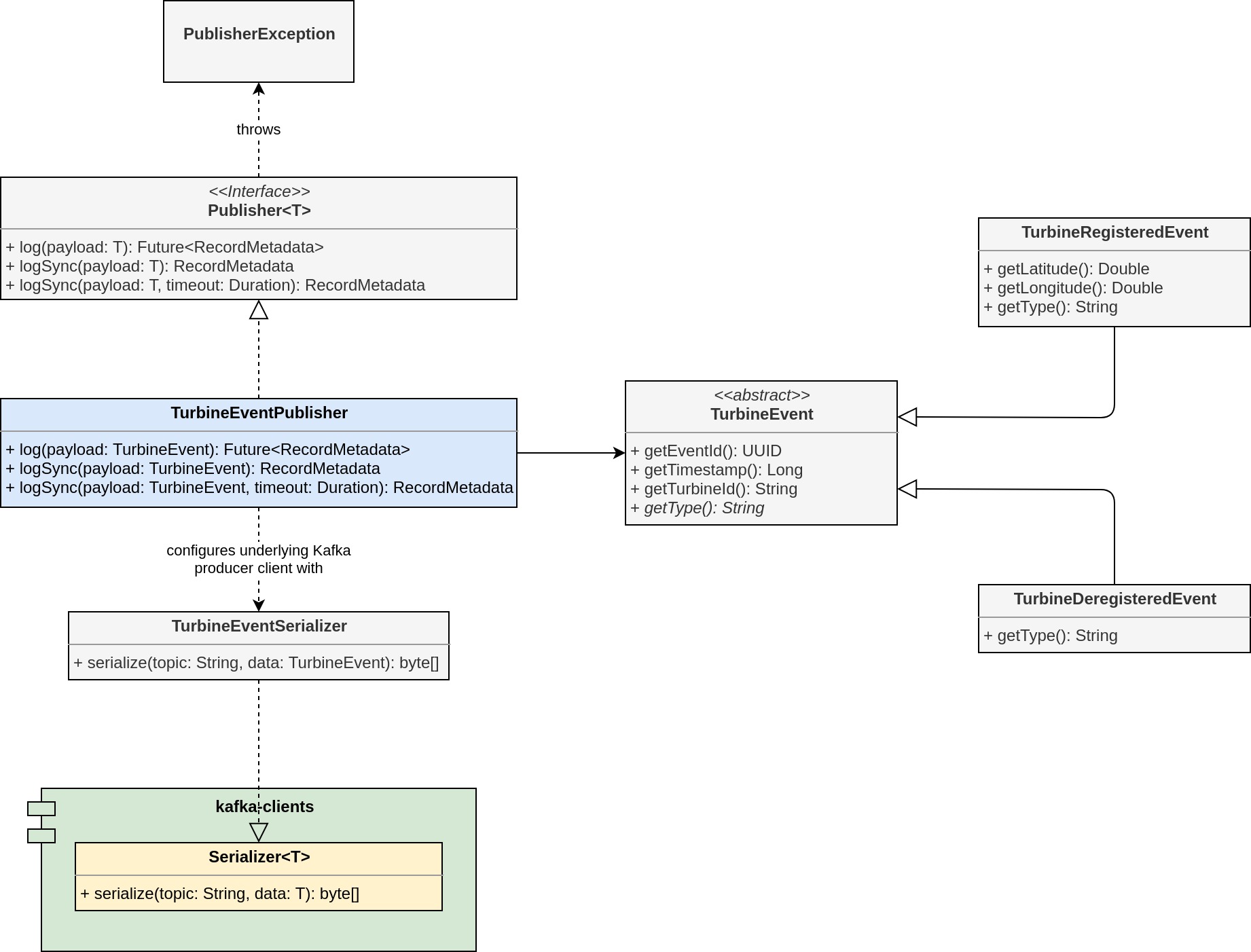
But still, this example is complex enough to raise the following question: How do we test the implementation and make sure that all of the components - our Jackson-annotated POJOs, the serializer and of course the publishing logic itself - integrate not only with each other, but also with a live Kafka deployment?
Enter Kafka for JUnit. Kafka for JUnit is a testing library build around the embeddable components of Kafka as well as the Kafka clients library. It is designed with ease of use in mind; you can quickly fire up an embedded Kafka cluster using default parameters or adjust its settings as you see fit. It comes with a bunch of client abstractions for producing and consuming records, seamlessly integrated with a concise and clear API for interacting with the cluster.
Let's write a simple test that verifies that an event that was accepted by the TurbineEventPublisher has actually been written to its designated topic. Let's create a test called TurbineEventPublisherTest and bring up an embedded Kafka cluster with default settings.
import static net.mguenther.kafka.junit.EmbeddedKafkaCluster.provisionWith;
import static net.mguenther.kafka.junit.EmbeddedKafkaClusterConfig.defaultClusterConfig;
public class TurbineEventPublisherTest {
private EmbeddedKafkaCluster kafka;
@BeforeEach
void setupKafka() {
kafka = provisionWith(defaultClusterConfig());
kafka.start();
}
@AfterEach
void tearDownKafka() {
kafka.stop();
}
}
The API of Kafka for JUnit has been designed with great care when naming methods. Factory methods that create the builders used to parameterize the cluster configuration or a write/read operation are class methods. Thus, I'll be using static imports frequently in order to improve the readability and conciseness of tests.
The next step is to write the actual test. Let me walk you through the test line-by-line.
Step 1. Create an instance of the subject-under-test, TurbineEventPublisher using the active brokers of the embedded cluster as bootstrap servers. All operations that Kafka for JUnit offers are accessible using class EmbeddedKafkaCluster. For instance, it provides us with a method getBrokerList() that yields the connection information for all active brokers and be fed directly into the configuration using the ProducerConfig.BOOTSTRAP_SERVERS_CONFIG parameter.
var config = Map.<String, Object>of(
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafka.getBrokerList());
var publisher = new TurbineEventPublisher("turbine-events", config);
Step 2. Create an instance of TurbineRegisteredEvent.
var event = new TurbineRegisteredEvent("1a5c6012", 49.875114, 8.978702);
Step 3. Use the subject-under-test to publish the TurbineRegisteredEvent.
publisher.log(event);
Step 4. Observe the target topic for some (configured) amount of time and see if a single record is written to it. If Kafka for JUnit is unable to observe that the expected number of records has been written to the topic, it will raise an AssertionError and thus fails the test case. The AssertionError contains a detailed message on how many records were expected and how many have actually been observed.
kafka.observe(ObserveKeyValues.on("turbine-events", 1, TurbineEvent.class));
Observing a topic records all Kafka records that have been seen and returns those to the caller. In the aforementioned listing we did not assign the return value of observe to a local variable. This is fine, if you're test is only concerned with making sure that a certain amount of records have been written to the target topic. Using the default configuration, a key and value deserializer for String is used. This works in our case (even if we were using an Avro schema or what have you) as Strings are byte-safe.
But if we were to override the default configuration of the value deserializer for the observe operation, we could extract the records in their proper representation. Let's do this.
kafka
.observe(ObserveKeyValues.on("turbine-events", 1, TurbineEvent.class)
.with(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, TurbineEventDeserializer.class.getName()));
This returns a List<KeyValue<String, TurbineEvent>> and we can use the Java Streams API to extract the first KeyValue<String, TurbineEvent> we find.
var consumedRecord = kafka.observe(on("turbine-events", 1, TurbineEvent.class)
.with(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, TurbineEventDeserializer.class.getName()))
.stream()
.findFirst()
.orElseThrow(AssertionError::new);
Step 5. Finally, we are able to assert that everything is in order.
assertThat(consumedRecord.getKey())
.isEqualTo("1a5c6012");
assertThat(consumedRecord.getValue())
.isInstanceOf(TurbineRegisteredEvent.class);
For the sake of completeness, here is the whole test class.
/** regular imports omitted for brevity **/
import static net.mguenther.kafka.junit.EmbeddedKafkaCluster.provisionWith;
import static net.mguenther.kafka.junit.EmbeddedKafkaClusterConfig.defaultClusterConfig;
import static net.mguenther.kafka.junit.ObserveKeyValues.on;
import static org.assertj.core.api.Assertions.assertThat;
public class TurbineEventPublisherTest {
private EmbeddedKafkaCluster kafka;
@BeforeEach
void setupKafka() {
kafka = provisionWith(defaultClusterConfig());
kafka.start();
}
@AfterEach
void tearDownKafka() {
kafka.stop();
}
@Test
void shouldPublishTurbineRegisteredEvent() throws Exception {
var config = Map.<String, Object>of(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafka.getBrokerList());
var publisher = new TurbineEventPublisher("turbine-events", config);
var event = new TurbineRegisteredEvent("1a5c6012", 49.875114, 8.978702);
publisher.log(event);
var consumedRecord = kafka.observe(on("turbine-events", 1, TurbineEvent.class)
.with(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, TurbineEventDeserializer.class.getName()))
.stream()
.findFirst()
.orElseThrow(AssertionError::new);
assertThat(consumedRecord.getKey()).isEqualTo("1a5c6012");
assertThat(consumedRecord.getValue()).isInstanceOf(TurbineRegisteredEvent.class);
}
}
And that's it!
Kafka for JUnit comes with many more features, like filtering capabilities when consuming records / observing a topic or fault injectors that fail transactions on purpose so that you can exercise the resilience of your components. Check out the comprehensive user's guide to learn more!
We'll be writing integration tests for the read-path in the next article.

